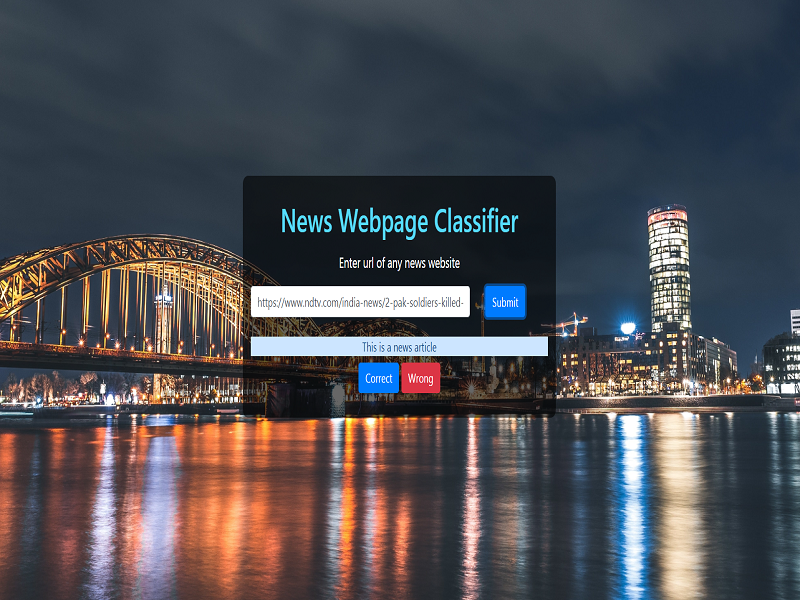
A multiclass classifier to indentify topics/ subjects of news articles.
This system classifies web based articles as news , gadgets and sports based on a probablistic learning approach called as the Naive Bayes Algorithm implemented in python making use of scikit-learn tool.
Initially a web crawler is built using Beautiful Soup Python module that scraps data from different news sites in order to generate a dataset that can be used for training the model. Python NLTK module is used for preprocessing this data such as tokenization, stop words removal, lemmatization etc.
A bag of words model is then generated from the preprocessed data which is segmented into training set and test set to determine the model's efficiency. A GaussianNB is then trained on the data for prediction in the test set. Dynamic training option is also enabled which means that the model is trained again on misclassification.

Kamini Kotekar
Data Scientist
Data Science graduate